Inca Digital’s Investigation Team is often tasked with collecting hidden data on crypto market participants. Although the blockchain space supplies troves of open data to sift through, trading venue activity often remains a mystery due to unreliable trade data and a lack of transparency from trading venue owners. To fill these data gaps, we leverage a variety of Natural Language Processing (NLP) techniques that can produce reliable datasets based on the digital footprint of crypto users. In the example below, we show how particular exchange users can be identified and geotagged.
Identifying Traders
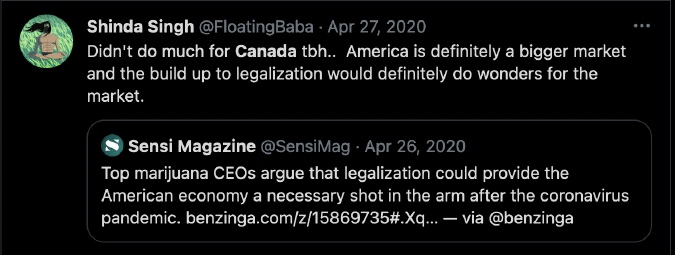
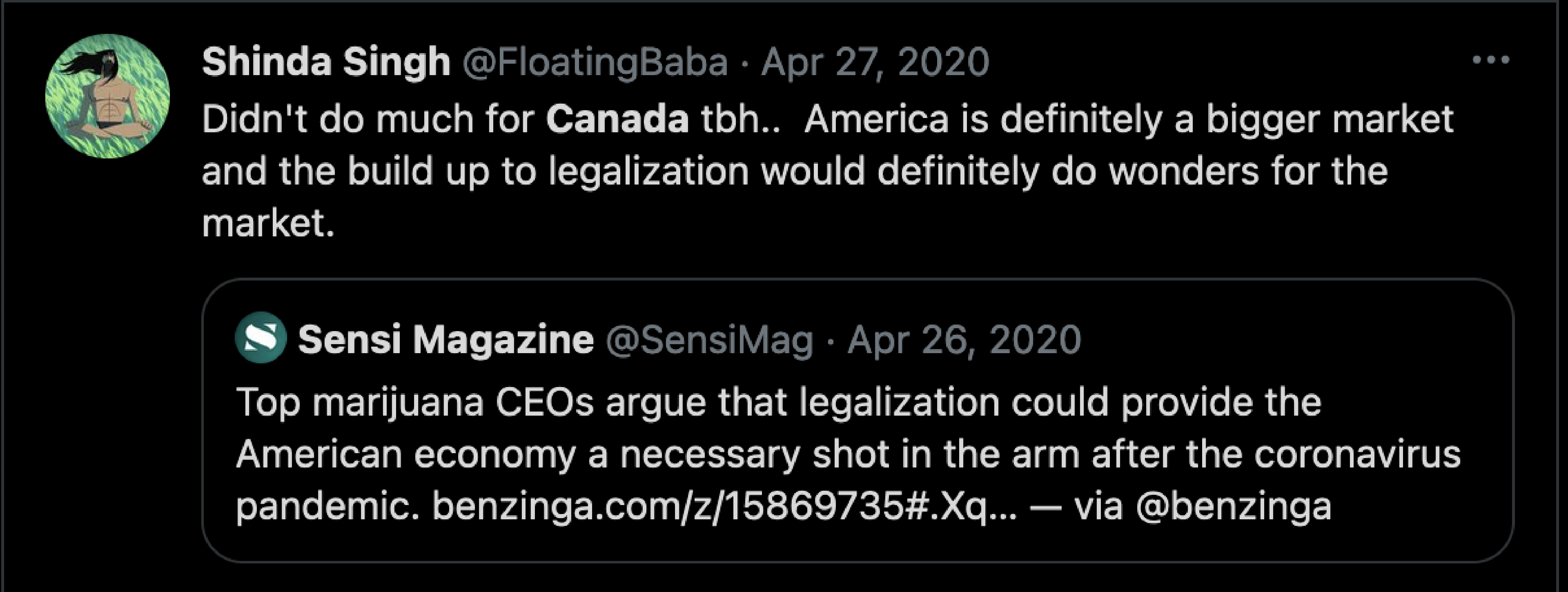
To underline the importance of such datasets, we take derivatives traders operating on the major derivatives venues and try to show that their geographic locations are far more diverse than what is claimed by the exchange operators and is allowed by local securities regulations.
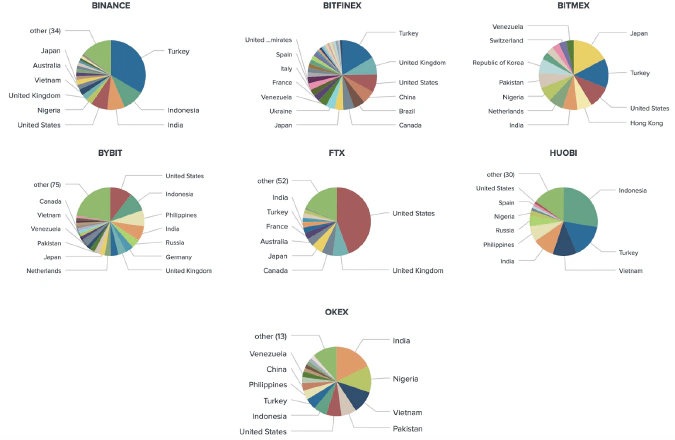
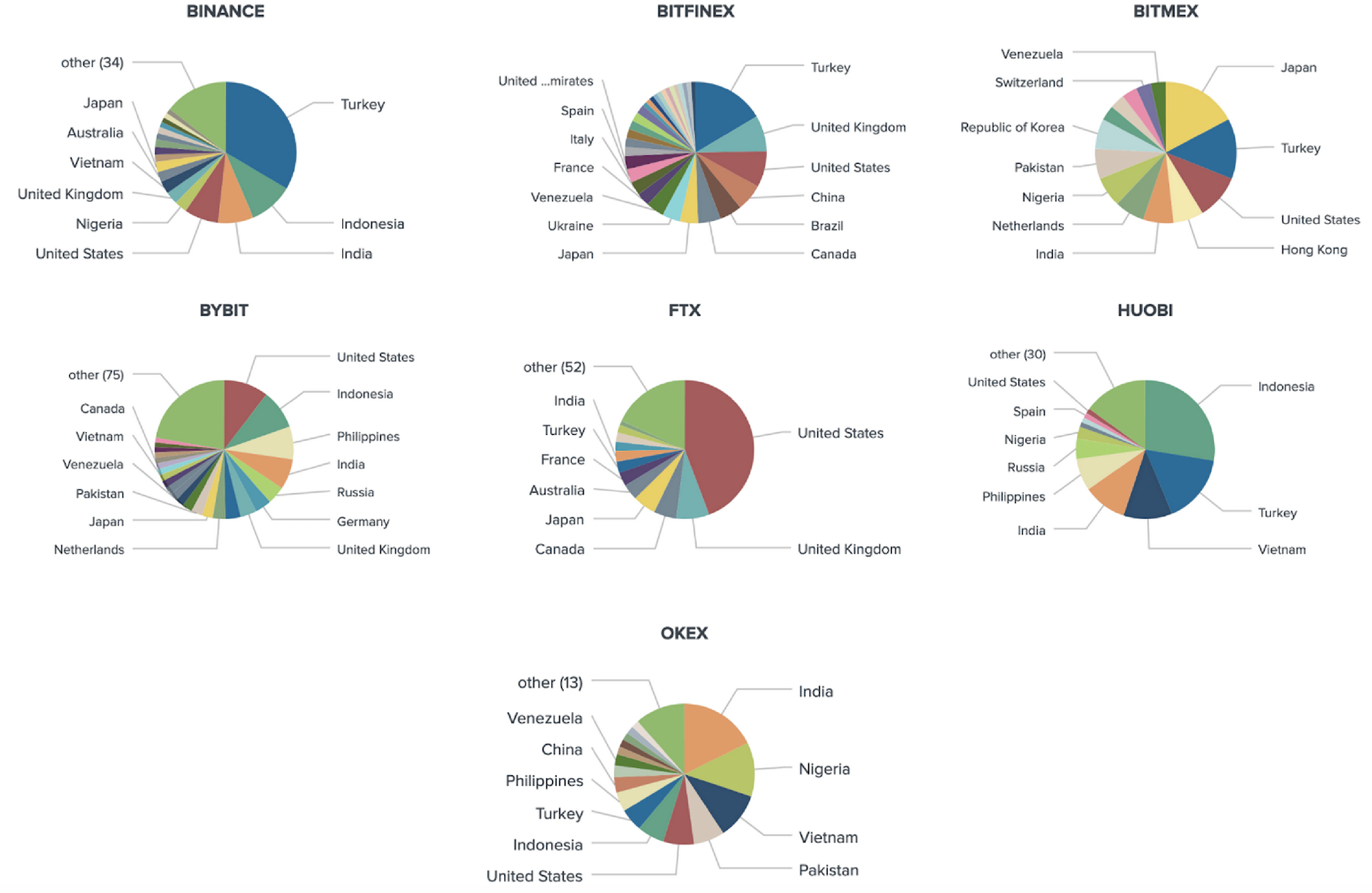
For this report, we include in our sample some popular derivatives platforms such as Bybit, Bitfinex, FTX, Binance Futures, BitMEX, OKEx, and Huobi Futures. Most of them are providing derivatives trading as their major service along with spot markets.
To start, we needed to identify platform users who are actively engaged in derivatives trading, rather than trading spot or just being curious about the exchange website or its activities. For this, we trained BERT models on a small set of known traders’ Tweets and analyzed unique embeddings that trigger a positive classification. This approach helped us discover particular tweet patterns that are inherent in those Twitter users who are involved in trading on derivatives platforms.
The tweet patterns include PNL (profit and loss) proofs, a specific screenshot that displays a derivatives trade execution, a referral link posting, and tweets mentioning a UID (trader’s unique identifier) along with a support request.
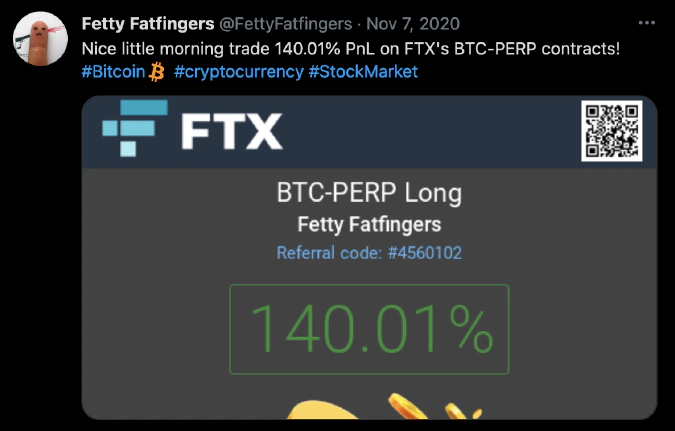
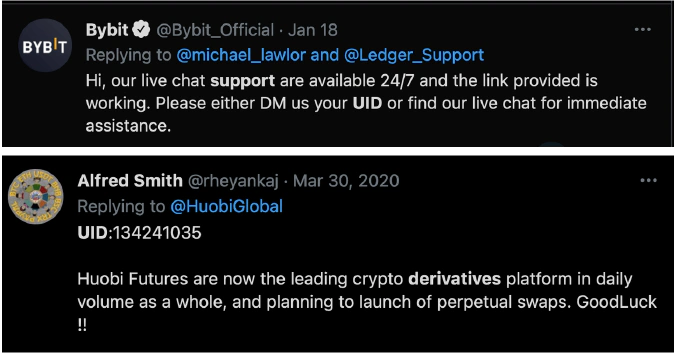
PNL proofs and the associated screenshots are meant to brag, showing a derivatives trader’s successful trades. The BERT model output for derivatives traders allowed us to collect a sample of 2,939 unique Twitter users engaged in derivatives trading on Bybit, FTX, Binance Futures, BitMEX, OKEx, Bitfinex and Huobi Futures.
Geotagging
When dealing with geolocating social network users, we typically employ 3 complementary components of the Inca’s NLP module: user profile description, language identification, and named entity recognition (NER).
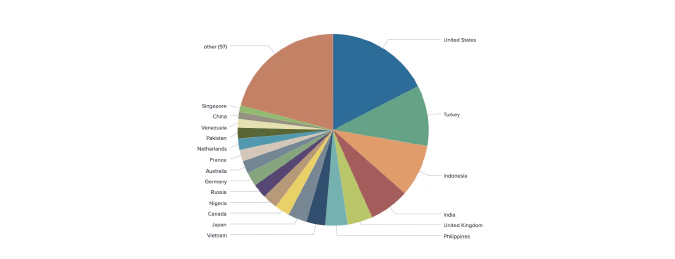
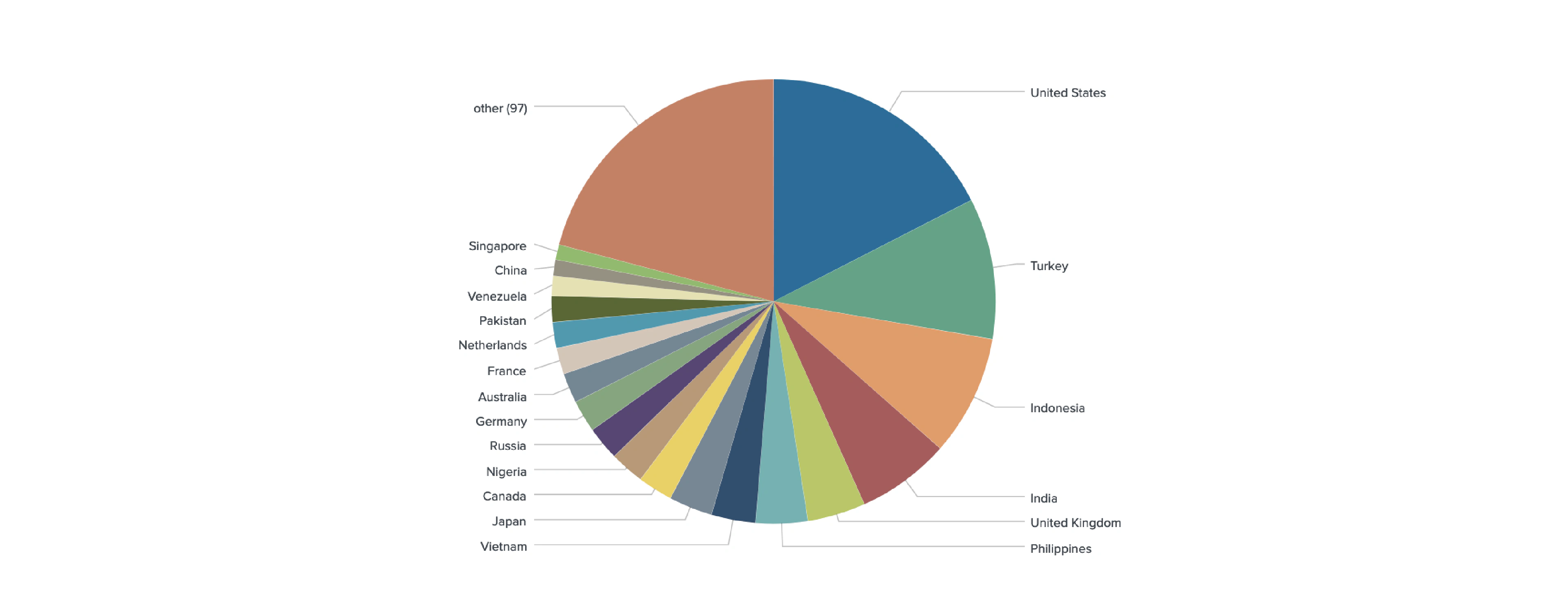
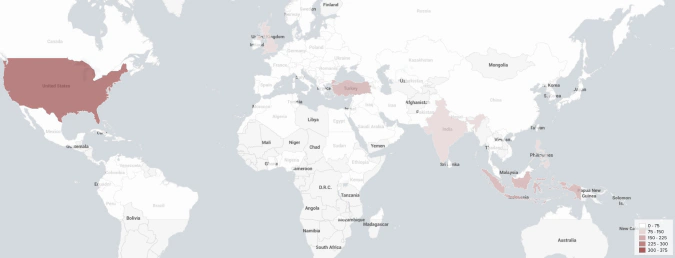
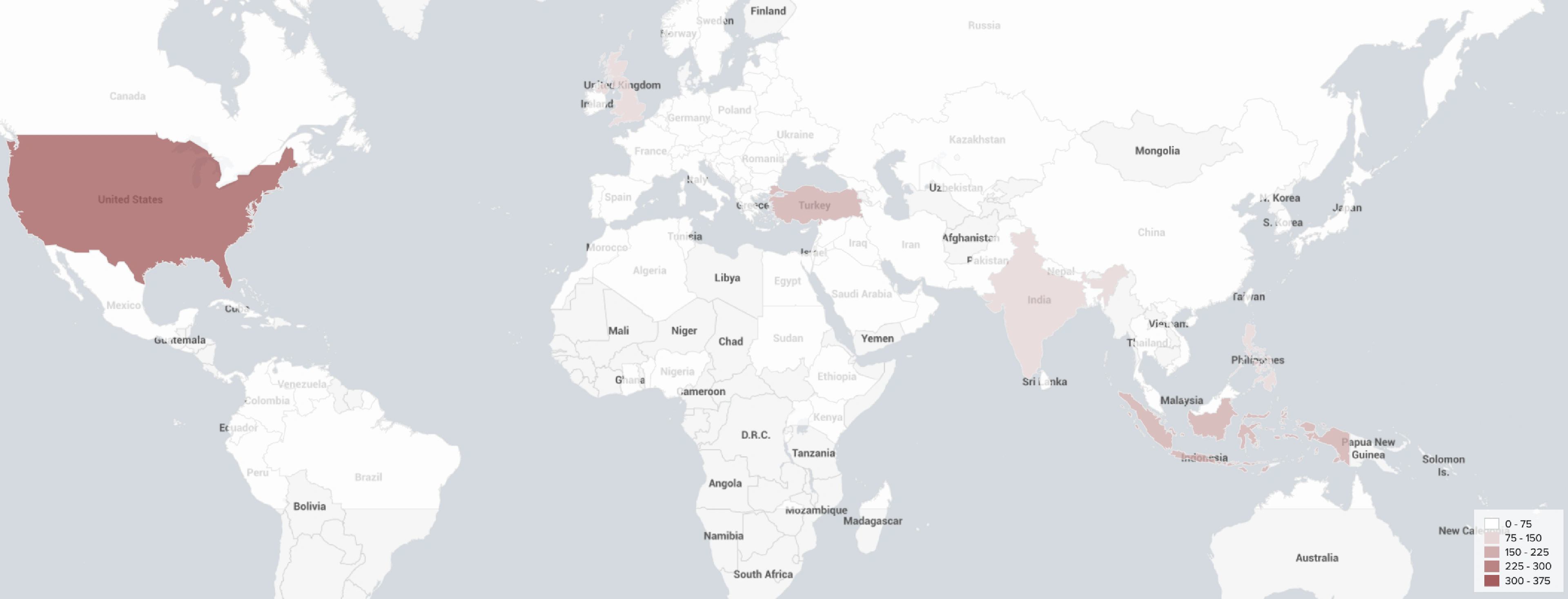
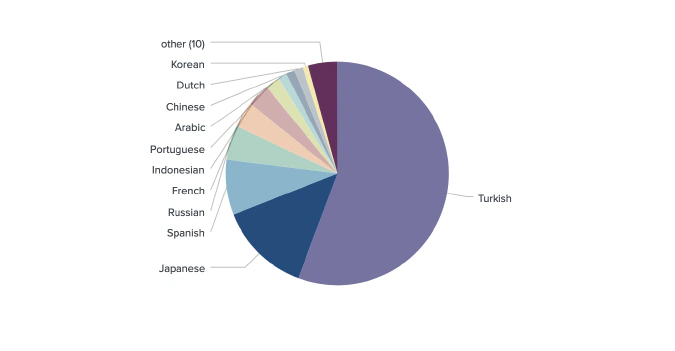
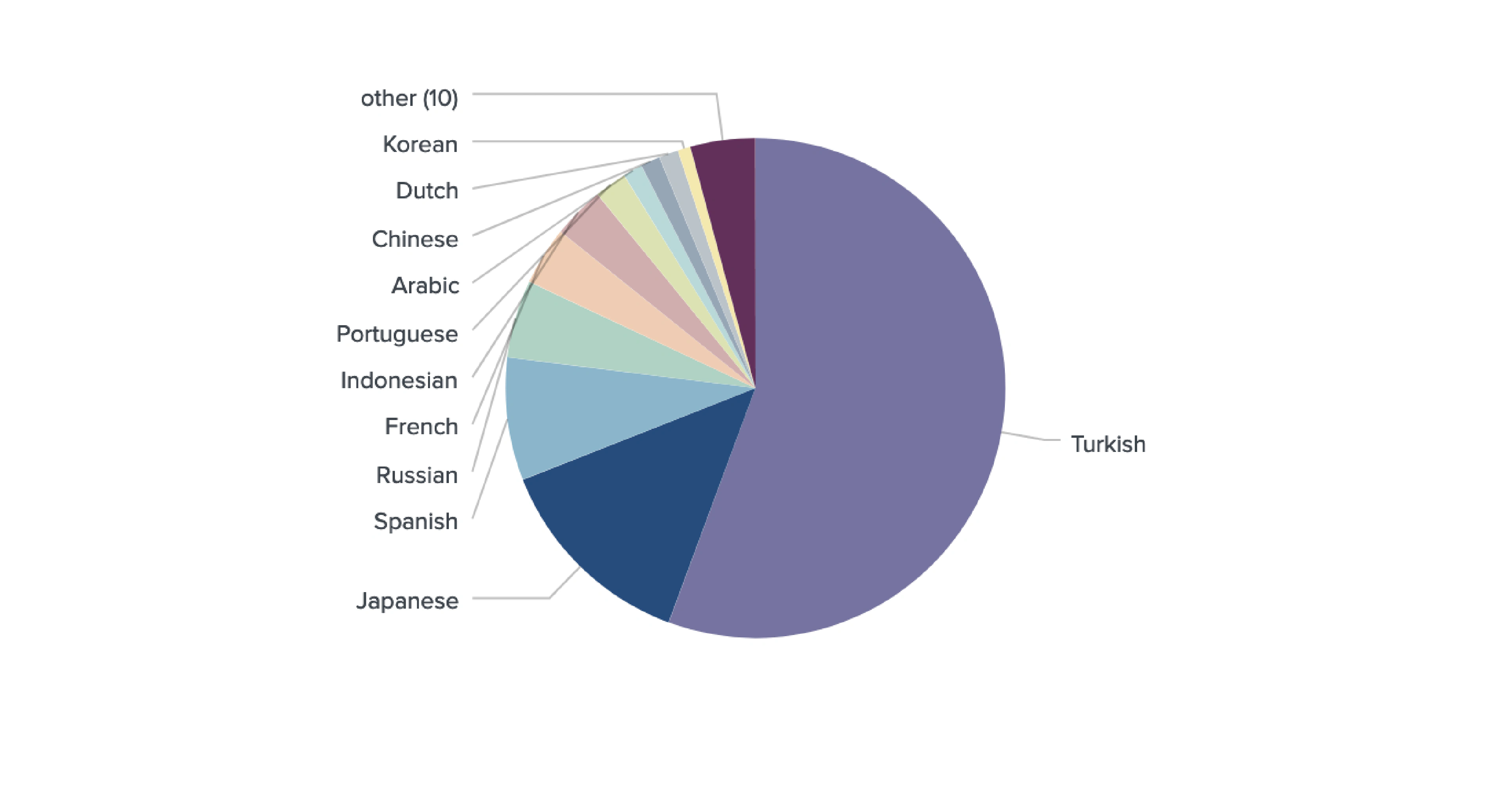
From our sample of 2,939 unique Twitter users engaged in derivatives trading on FTX, Huobi Futures, Binance Futures, OKEx, Bybit, Bitfinex, and Bitmex, we identified the locations of 2,164 traders globally, and 372 from the United States specifically.
User Profile Description
The simplest of the 3 geolocation methods analyzes user’s profile description. The geolocation mentions, residing in the user’s bio, allowed us to identify the location of 911 of the 2,939 derivatives traders sampled.
Language Identification
The language identification technique relies on utilizing geographically isolated languages to identify, with high confidence, where a user lives. It does not correlate with the User Profile Description data and provides a unique signal that can be overlaid on the other datasets to provide more accurate localization. In some cases, a regional variety of a language is characteristic of a particular region, which makes geotagging even more precise. The trader sample utilized in this analysis includes various dialects, such as Simplified and Traditional Chinese, as well as Latinized versions of Japanese, Hindi, and Korean. In the derivatives trader sample dataset, this approach allowed us to identify 21 unique spoken languages and identify the location of 189 out of 2,939 traders over 14 territories.
NER for Place Recognition
The final method is the most sophisticated, requiring a much more extensive speech sample collection and state-of-the-art multi-language Geographical Named Entity Recognition models. By running hundreds of tweets of each of the identified users through our models, NER geotagged 2,079 out of 2,939 derivative traders.
By referencing favorite coffee shops, upcoming concerts, ongoing elections, landmarks, and even traffic jams, Twitter users produce invaluable geotags that can be aggregated to predict the true residency of a derivatives trader, regardless of the statements made during their KYC onboarding process and the paperwork they provide to the trading venue.
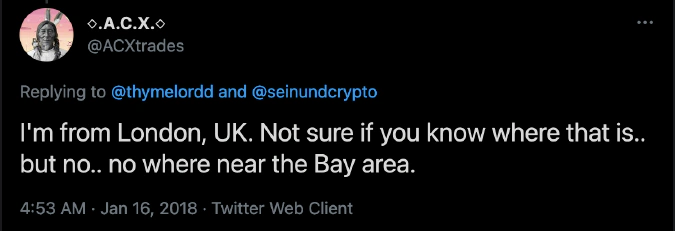
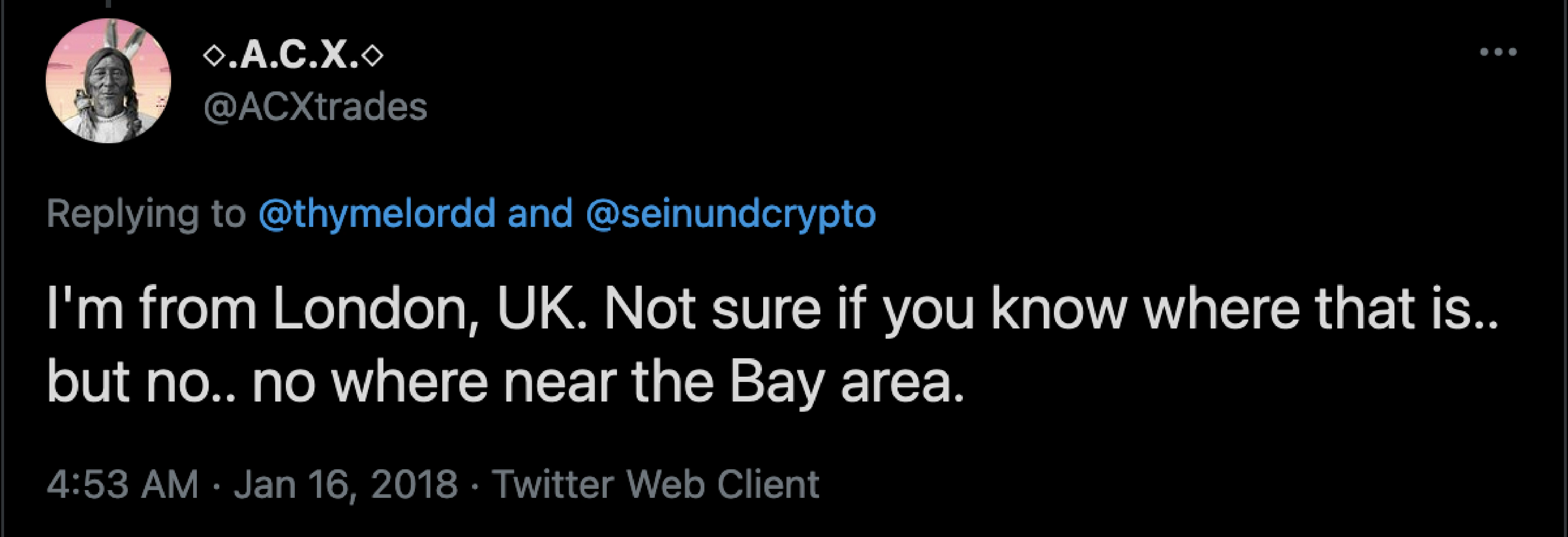


These tags are often much more reliable and precise than any other methods we use, enabling city-level granularity.
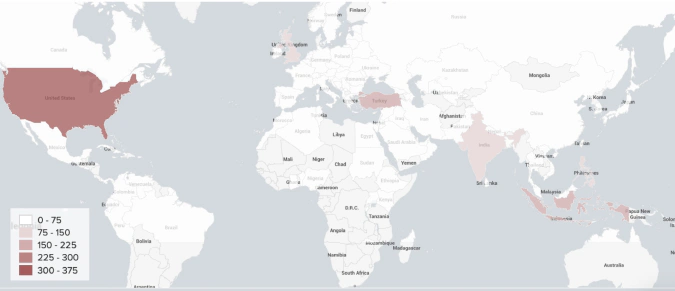
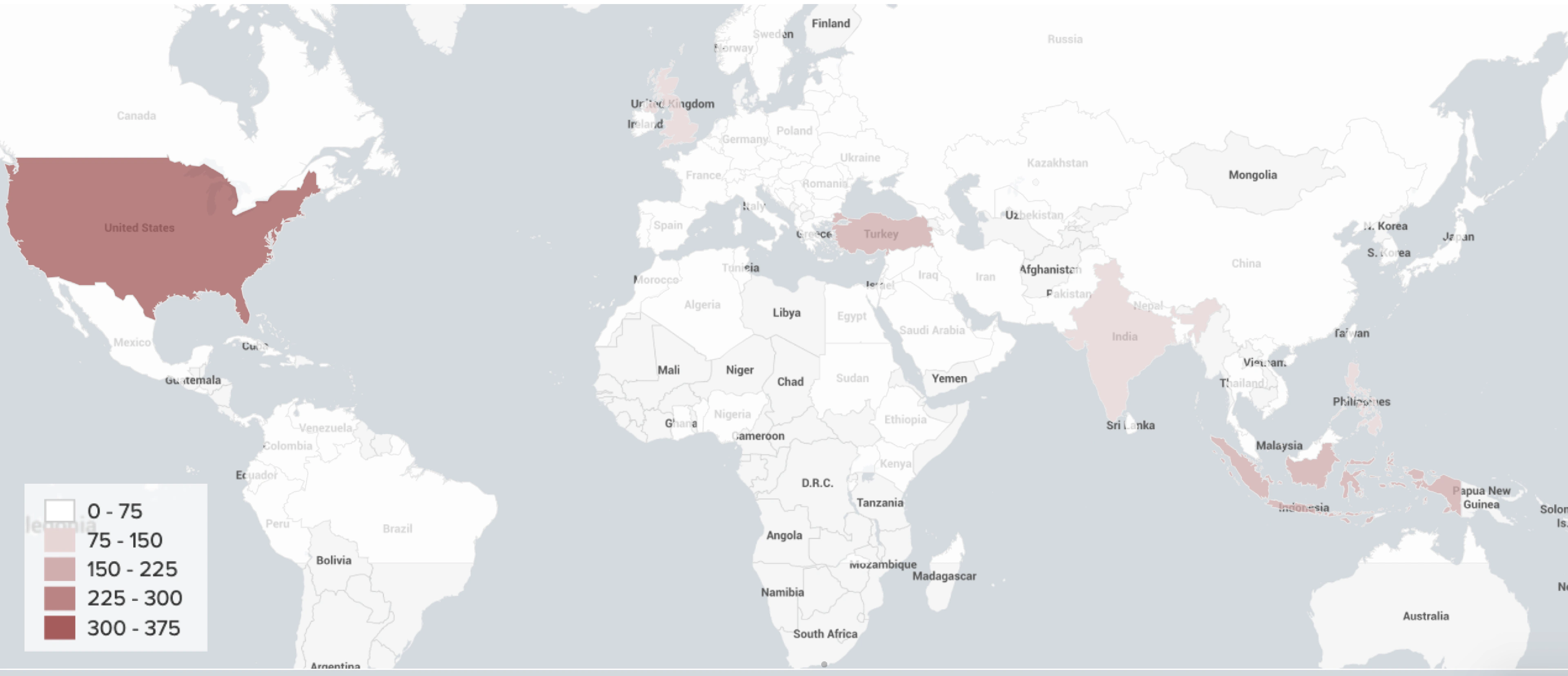
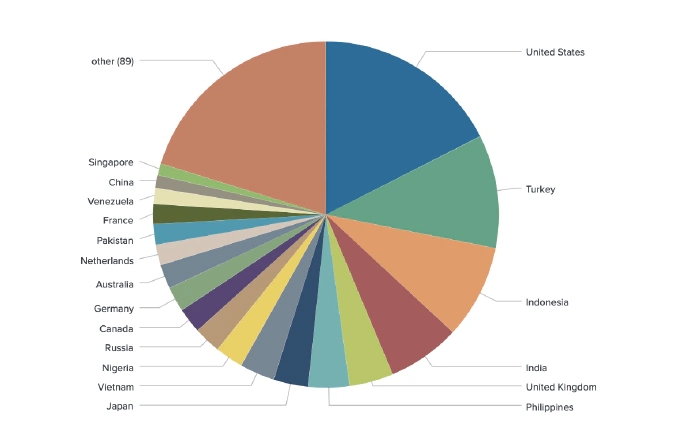
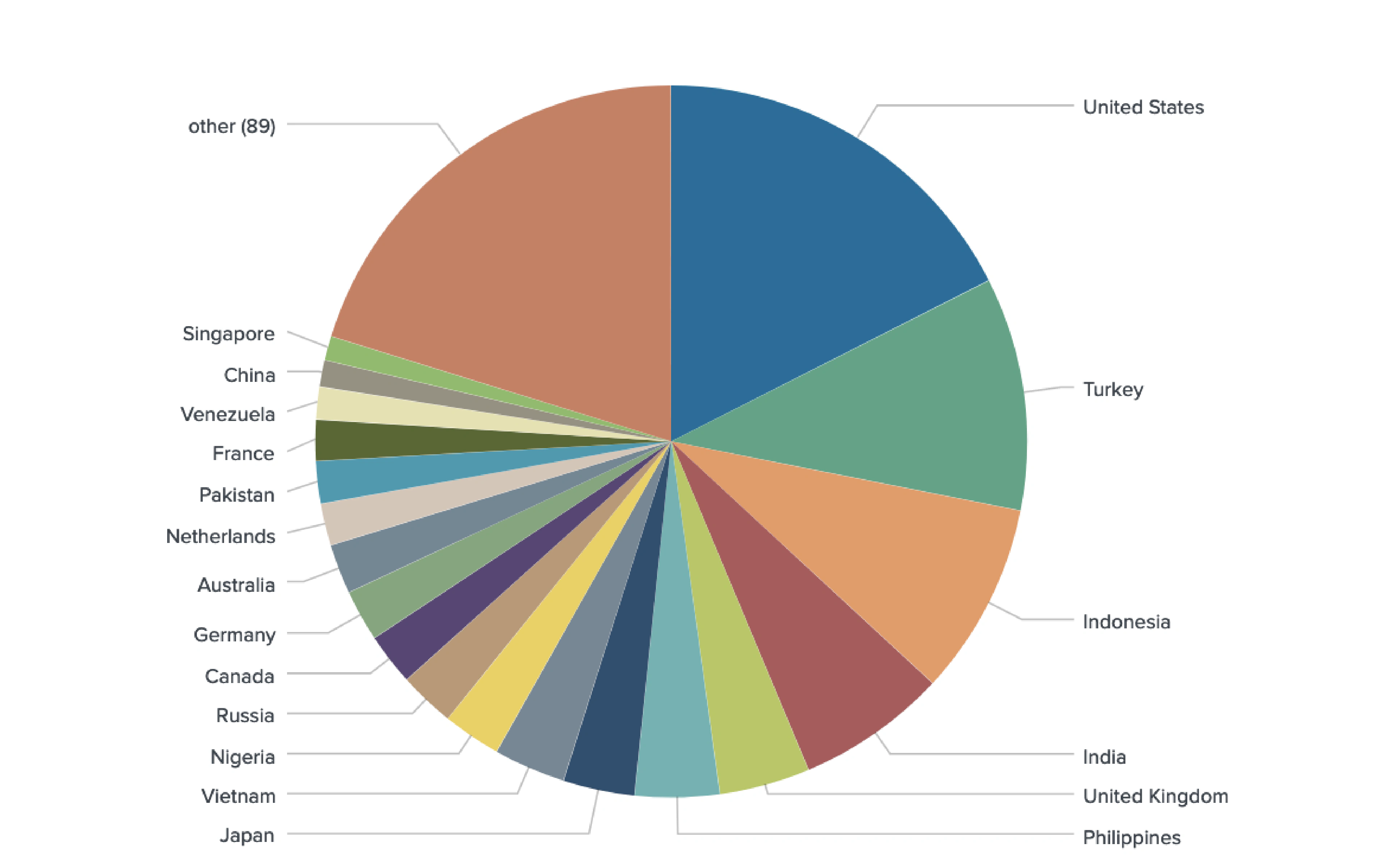
All Methods Combined
The true power of natural language processing for geotagging entities - crypto traders or otherwise - comes from combining all methods and overlaying geotags from multiple sources. This often gives enough corroborating evidence that an exchange user is actively trading certain financial products, rather than just visiting a website out of curiosity or using it for other purposes.
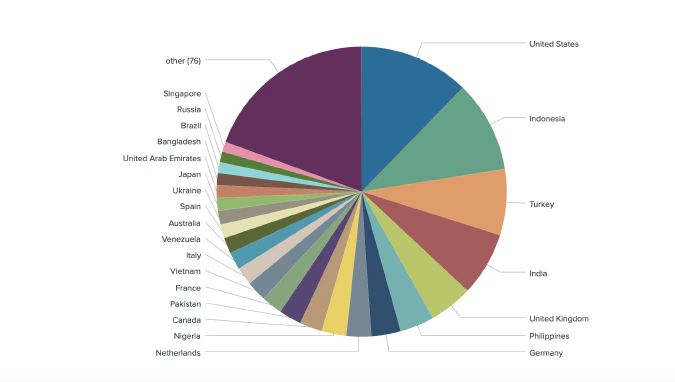
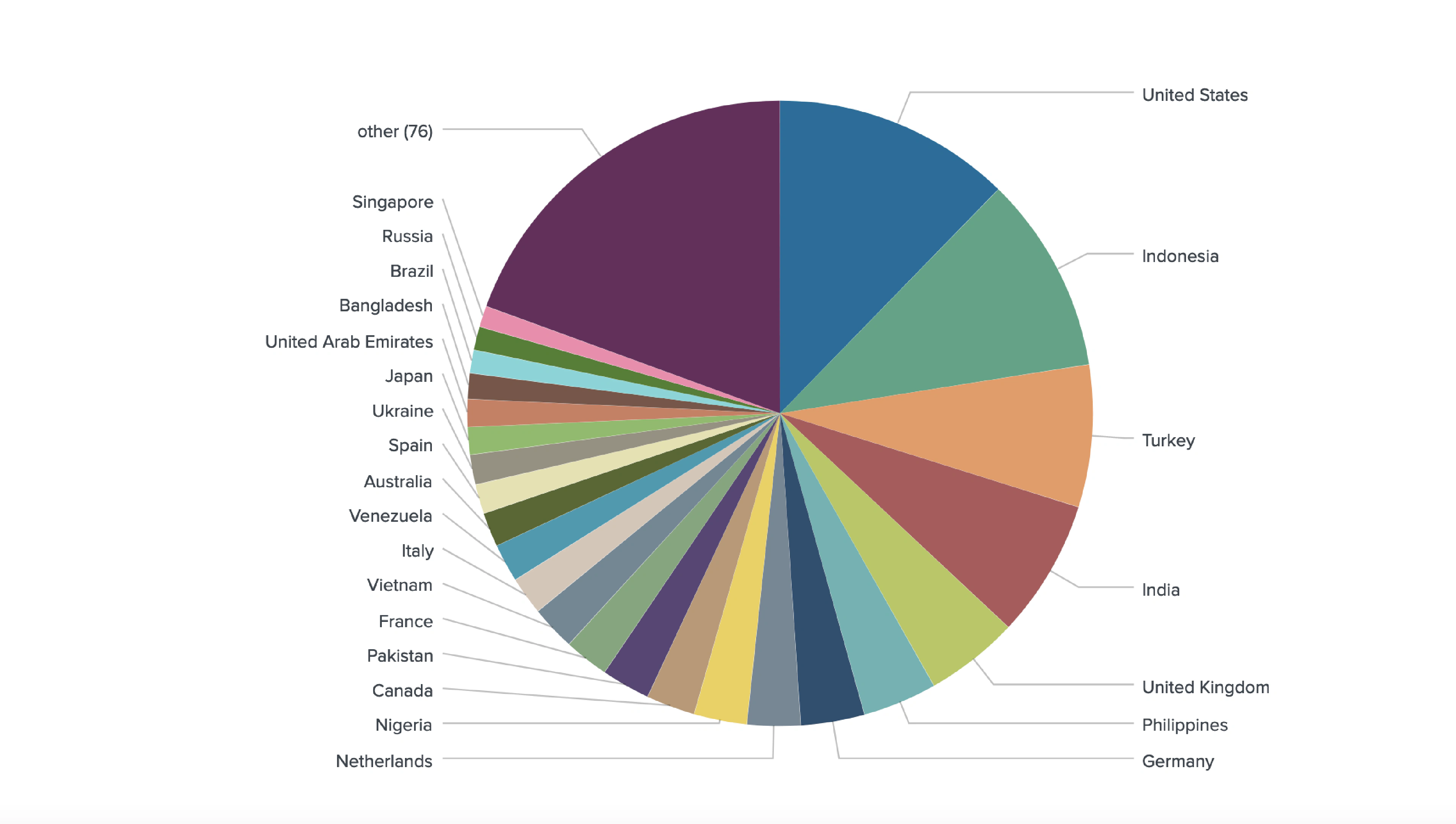
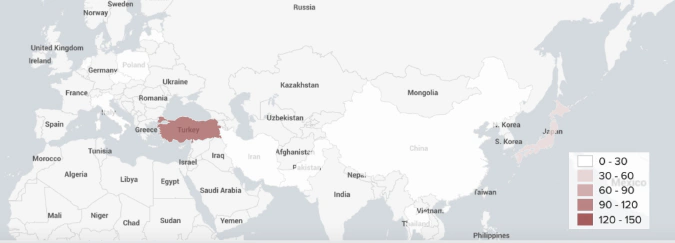
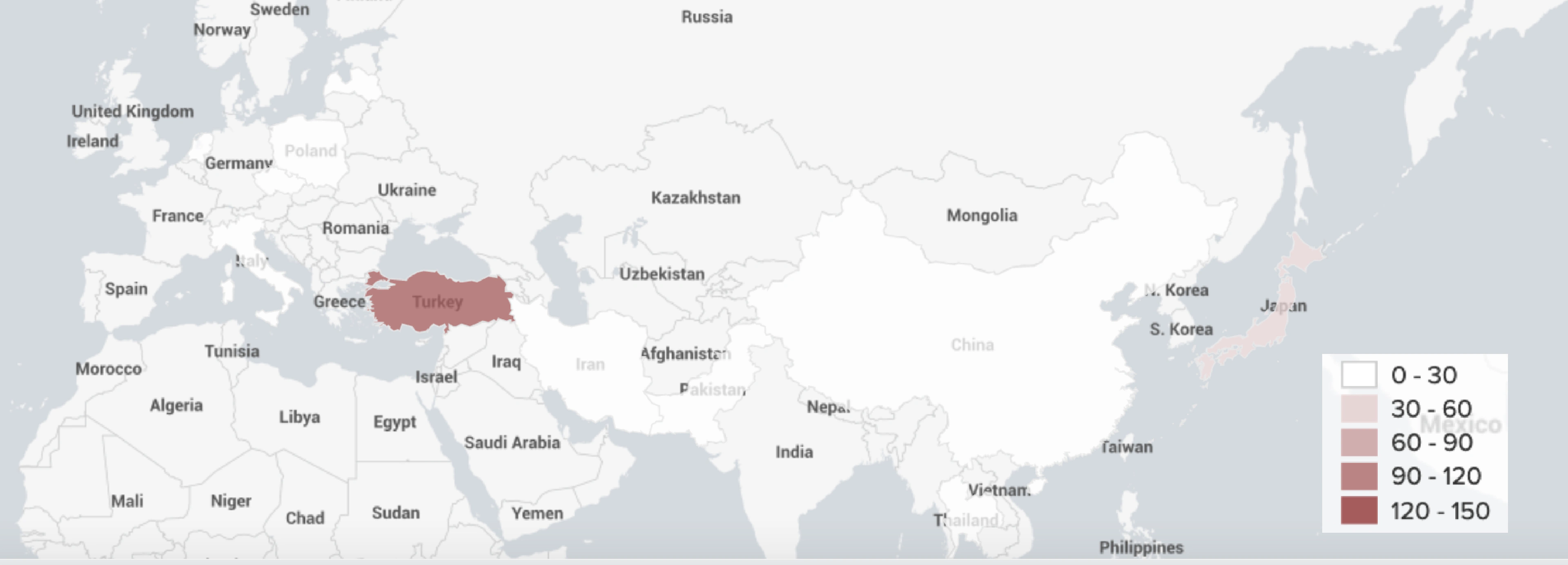
We geotagged 2,164 out of 2,939 unique derivative traders from 116 countries.
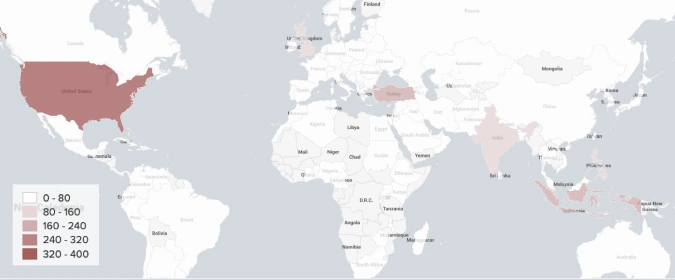
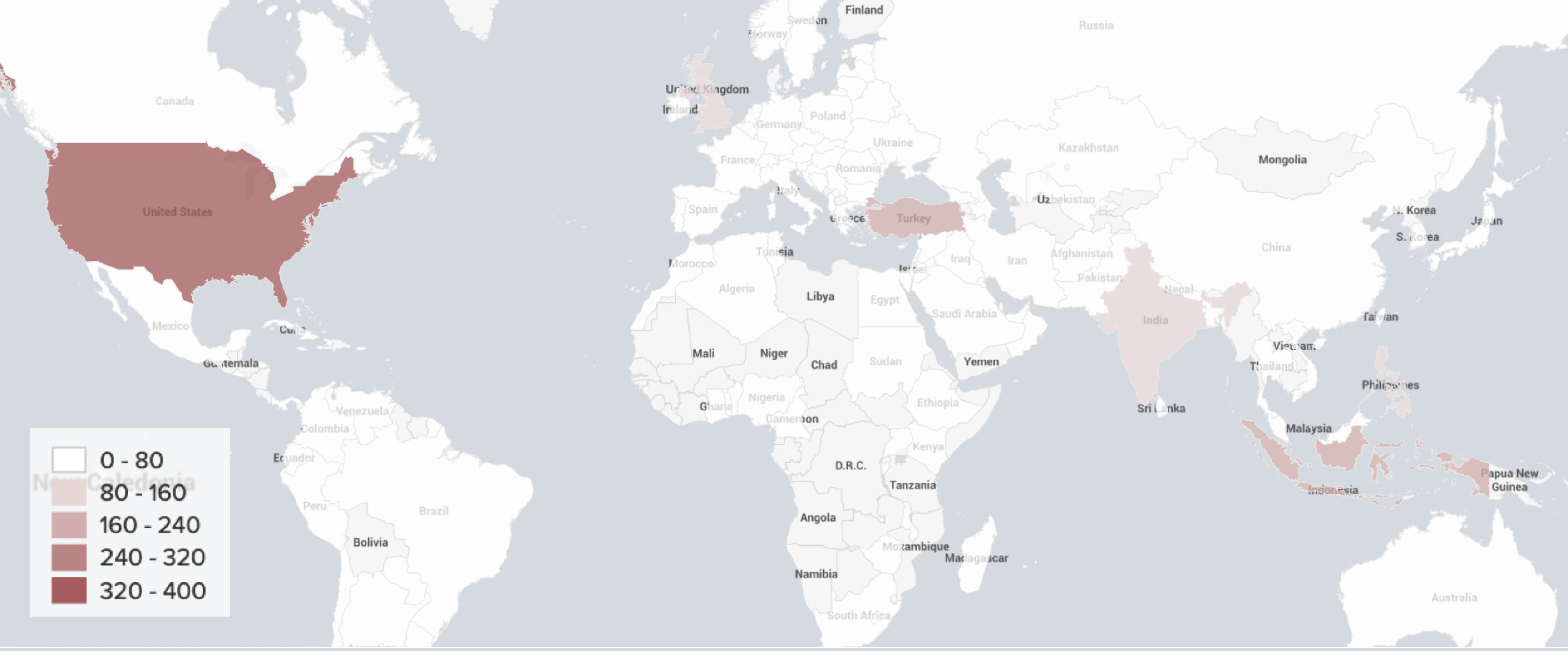
Trader Location (Venue Breakdown)
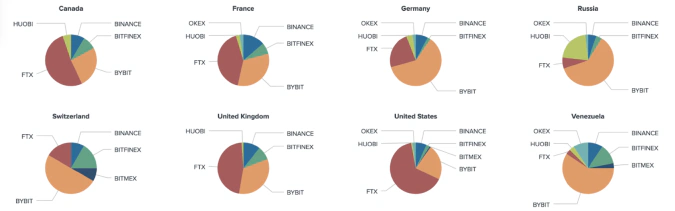
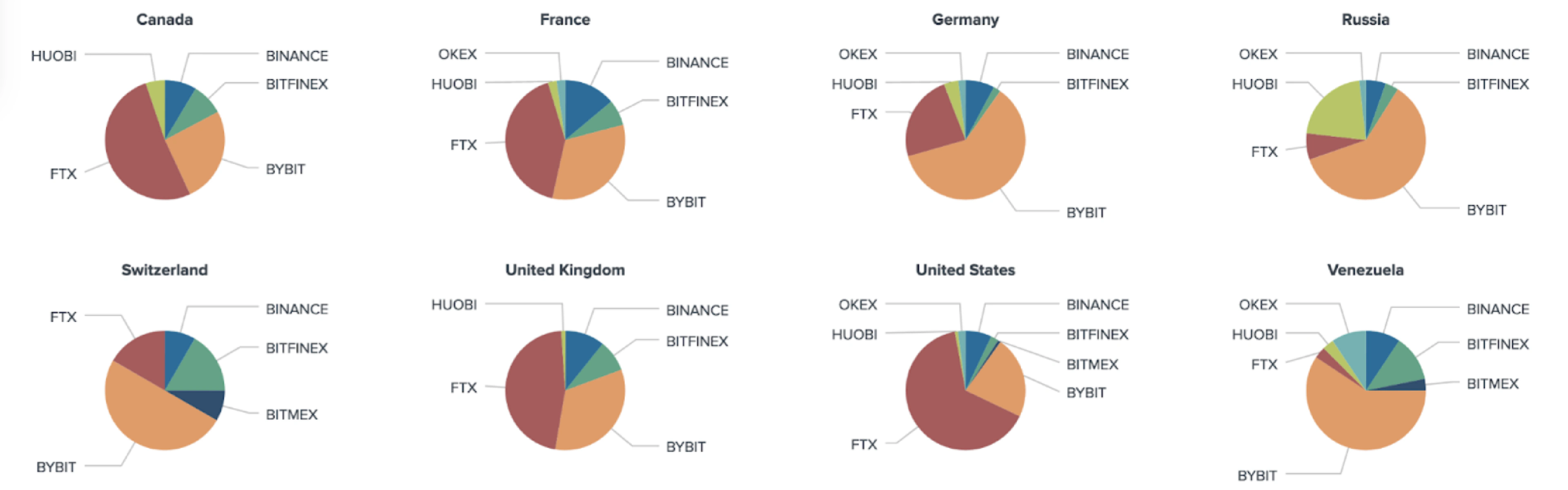
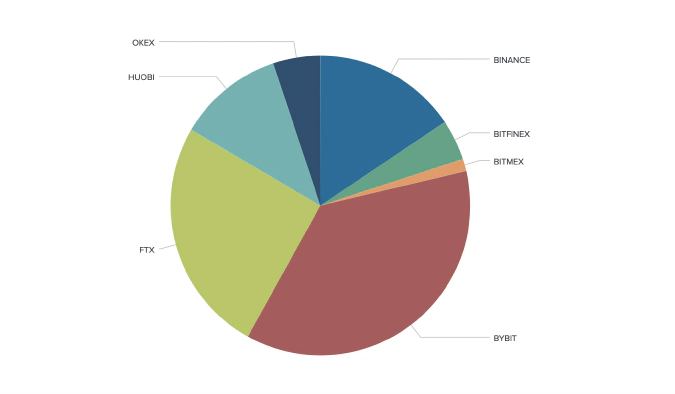
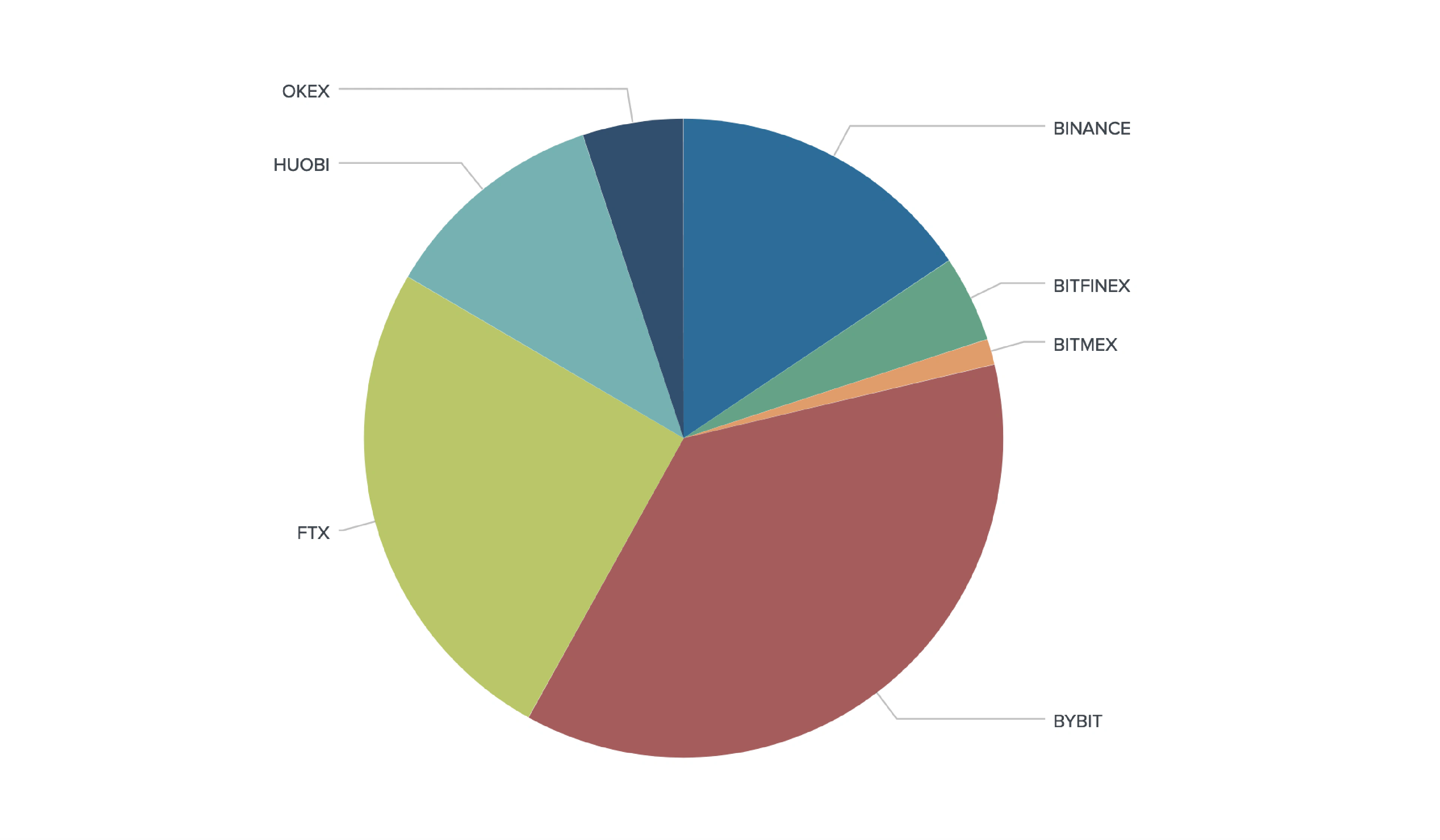
3-component Model and API Discrepancy


A number of geotagged users have different location information acquired from the User Profile Description relative to the model estimation. According to the model’s estimate, most of the users that are supposed to reside in the United States, United Kingdom and Turkey, are showing other locations in their bio.
Trading venues often rely on IP address attribution-based filters, which are easy to circumvent by using a VPN with an exit node in another jurisdiction. NLP geolocation is not correlated to the actual traffic path and therefore resistant to such location spoofing methods.
The purpose of this analysis is not to single out any of the exchanges discussed in this report. In fact, we see similar problems with unregistered financial product offerings across most crypto trading venues with significant volumes.