Building on top of our crypto users mapping work featured in The Wall Street Journal, we enhanced our NLP models and expanded the scope of the analysis to include more trading venues and products.
We fed millions of social media posts into the model to get more precise results with higher confidence levels.
We increased geotagging granularity to map users on a state/province level.
Identifying traders
Within crypto, social media platforms are among the most valuable data sources for community discovery. Our NLP components process human-generated content and discover relationships between entities. By discovering unique media content patterns, they can identify users who are active on specific trading venues. A separate set of NLP models are trained to geotag these users using 4 methods that compliment each other.
Our previous attempts at geotagging crypto users with NLP concentrated on a very narrow, specific aim concerning derivatives traders utilizing major crypto exchanges. Subsequently, we have expanded the scope of our analysis to identify and locate spot traders on a wider range of trading platforms.
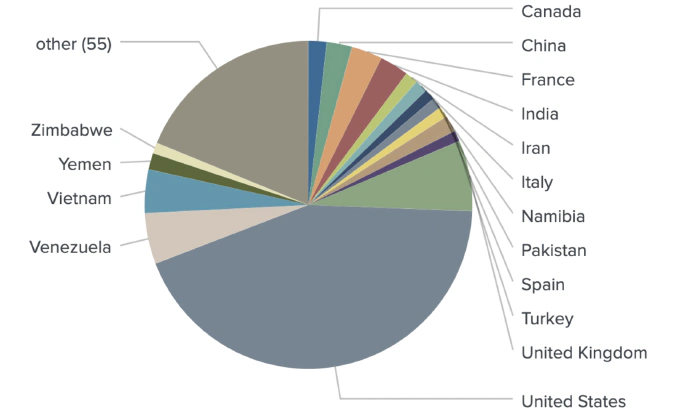
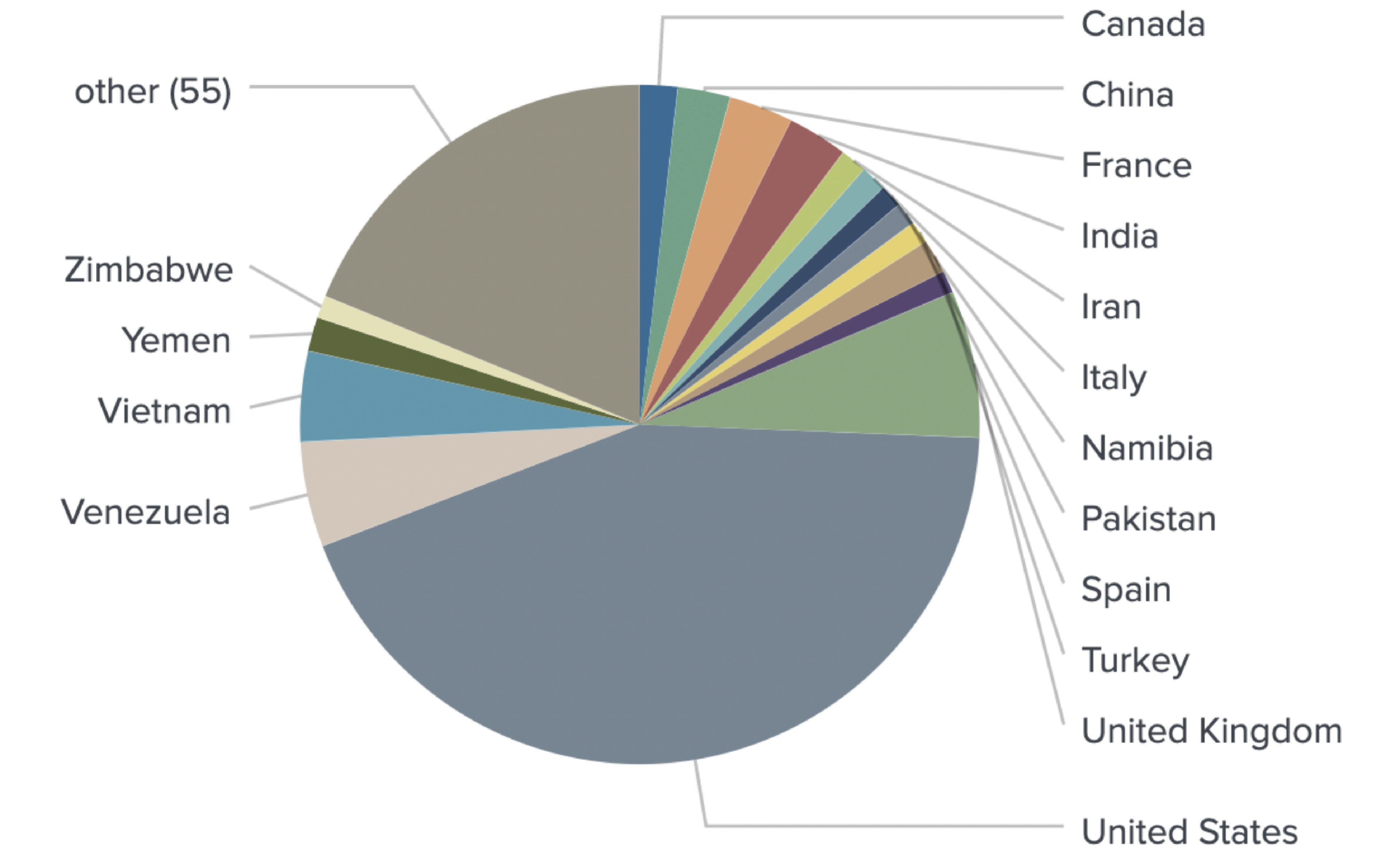
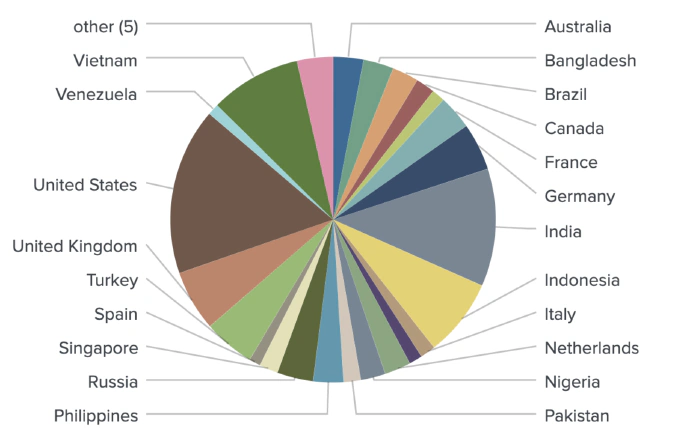
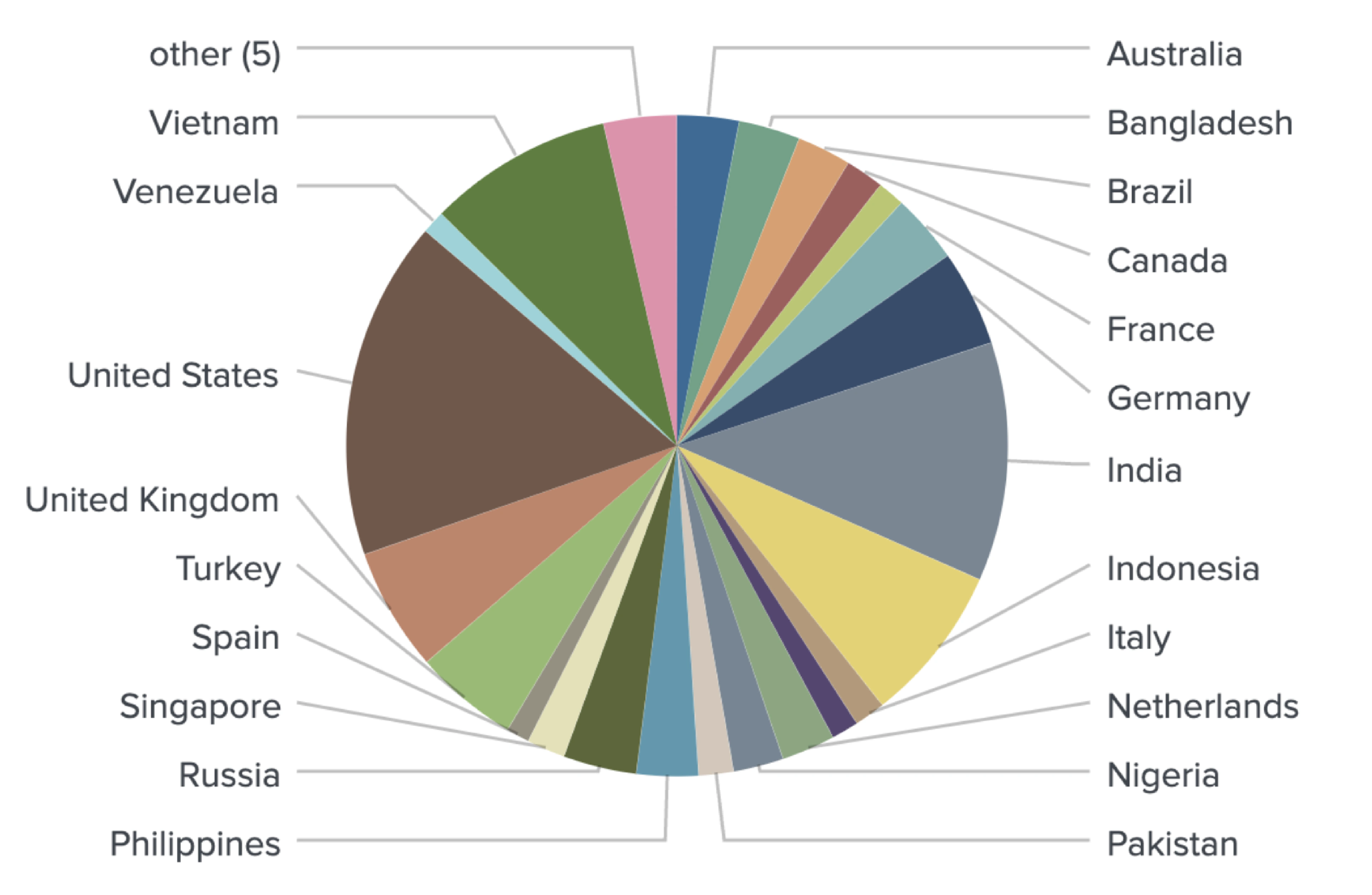
In this report, we focus on spot traders from well-known crypto venues such as Binance, Bitfinex, Coinbase, Huobi, Kraken, Gemini, OKEx, KuCoin, Bybit, BlockFi, Coinmama, Poloniex, Celsius, and Nexo. In order to identify users trading on these exchanges, we fed millions of social media posts into our NLP models in order to identify media content patterns specific to individual users. As an example, clear patterns were detected involving people interacting with trading venue support accounts, including mentions of support tickets and UIDs (trader’s unique identifier).
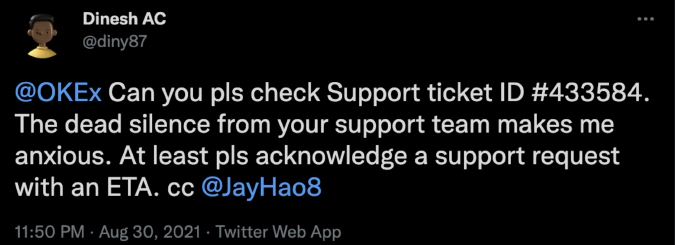
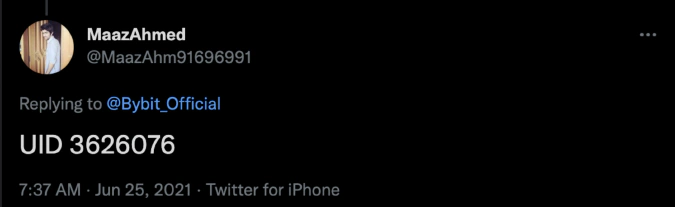
These classification models allowed us to collect an extensive dataset of spot market traders and attribute them to specific exchanges.
Geotagging users with NLP models
The revised geotagging model we developed for this round of analysis uses four separate data types. The four data types used in our model are Named Entity Recognition, Language Identification, User Profile Description, and Associated Connections’ Information. These data types were acquired from social media text in order to assign each user to a feature set based on both their posts and the locations of the users they follow.
Named Entity Recognition
One of the more sophisticated methods for obtaining geolocation information is via Named Entity Recognition (NER). Generally, NER models solve a sub-task of information extraction which aims to find and categorize named entities from text into predefined categories such as people and organization names, countries, cities, provinces, and so on. We used a deep neural network (DNN)-based model called mordecai that performs NER on social media posts and detects the country which is mentioned in the texts. Afterwards, all mentioned countries are aggregated for each specific user, forming a feature vector that is used in the final ensemble model.
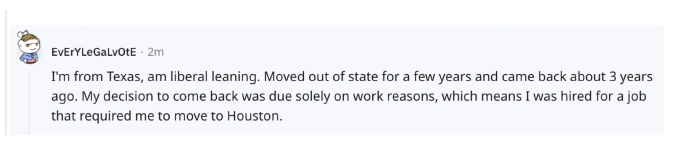
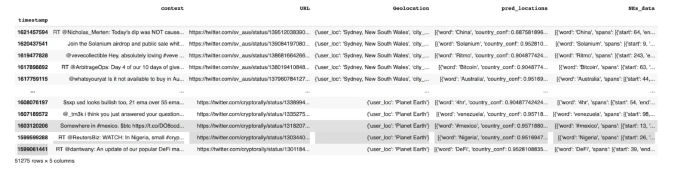
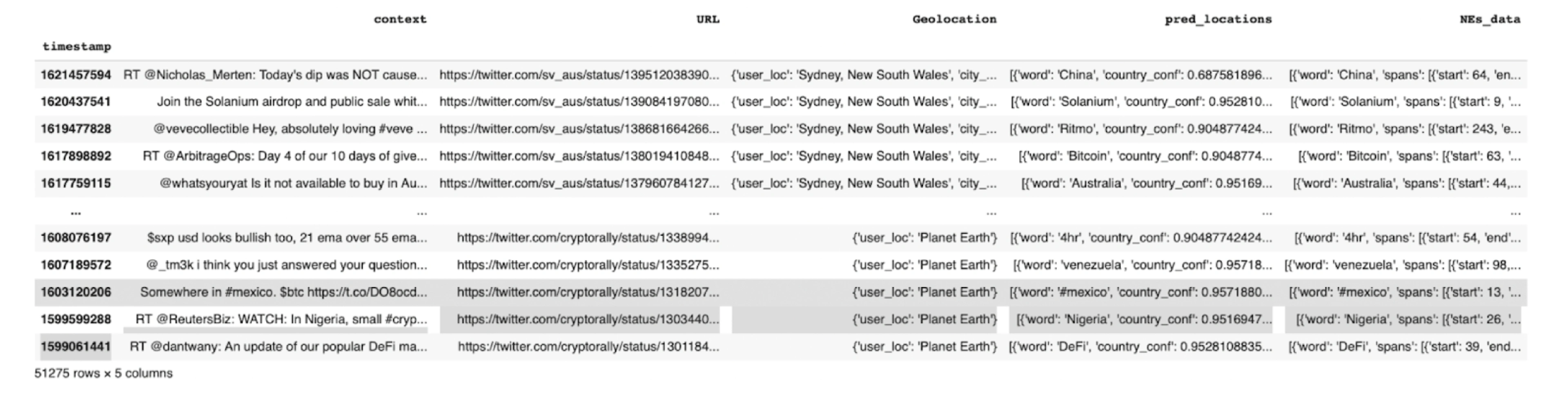
By running a massive media content dataset through our models, NER identified geolocations for 558 out of 1,298 users.
Language Identification
Language Identification component is a reliable source of geolocation data that analyzes and identifies languages specific to a certain territory. For this purpose, the ML model identifies in which language a text is written by leveraging three state-of-the-art open-source language identification algorithms: langid, langdetect and polyglot. The model currently covers 70 of the most frequently used languages across social media. The algorithms are combined to cancel-out each other’s errors, increasing the overall language identification performance. All of the identified languages are then aggregated for each specific user, normalized, and used to form a feature vector which goes into a final ensemble model. After running hundreds of social media posts through a Language Identification component, we received accurate geolocation predictions for 968 users.
User Profile Description
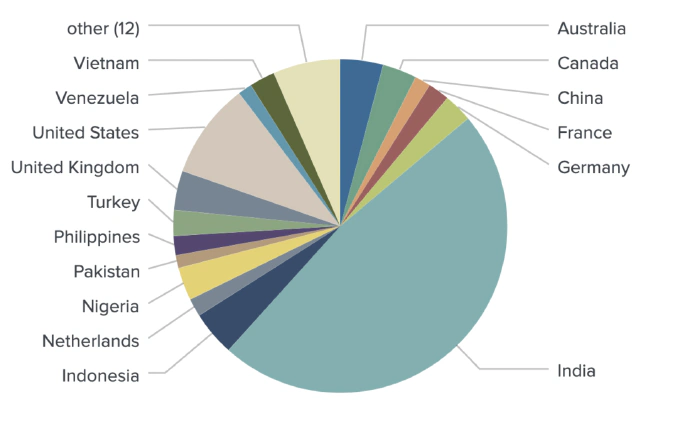
User Profile Description returns geotagging information specific to a user’s social media profile. This information is then one-hot encoded to form a feature vector for a final model. The geolocation data from the user’s profile returned geotags for 1,153 users from the 1,298 sample.
User’s Associated Connections
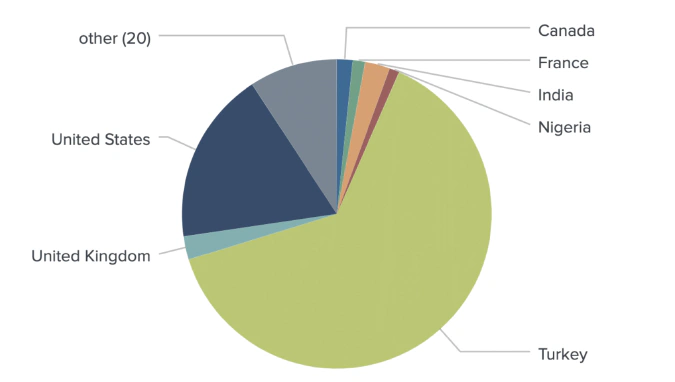
The last component of the geotagging model is information about user’s relationships. Similar to the User Profile Description step detailed above, the Associated Connections’ geolocation data derived from their Twitter bio and/or tweet metadata is then one-hot encoded to form a feature vector for the final model.
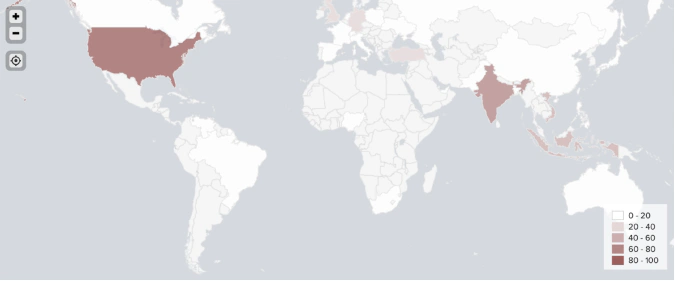
Ensemble geotagging model
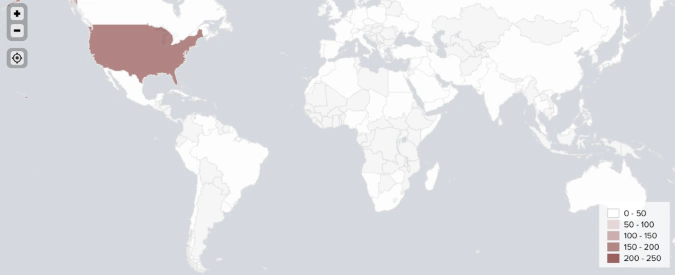
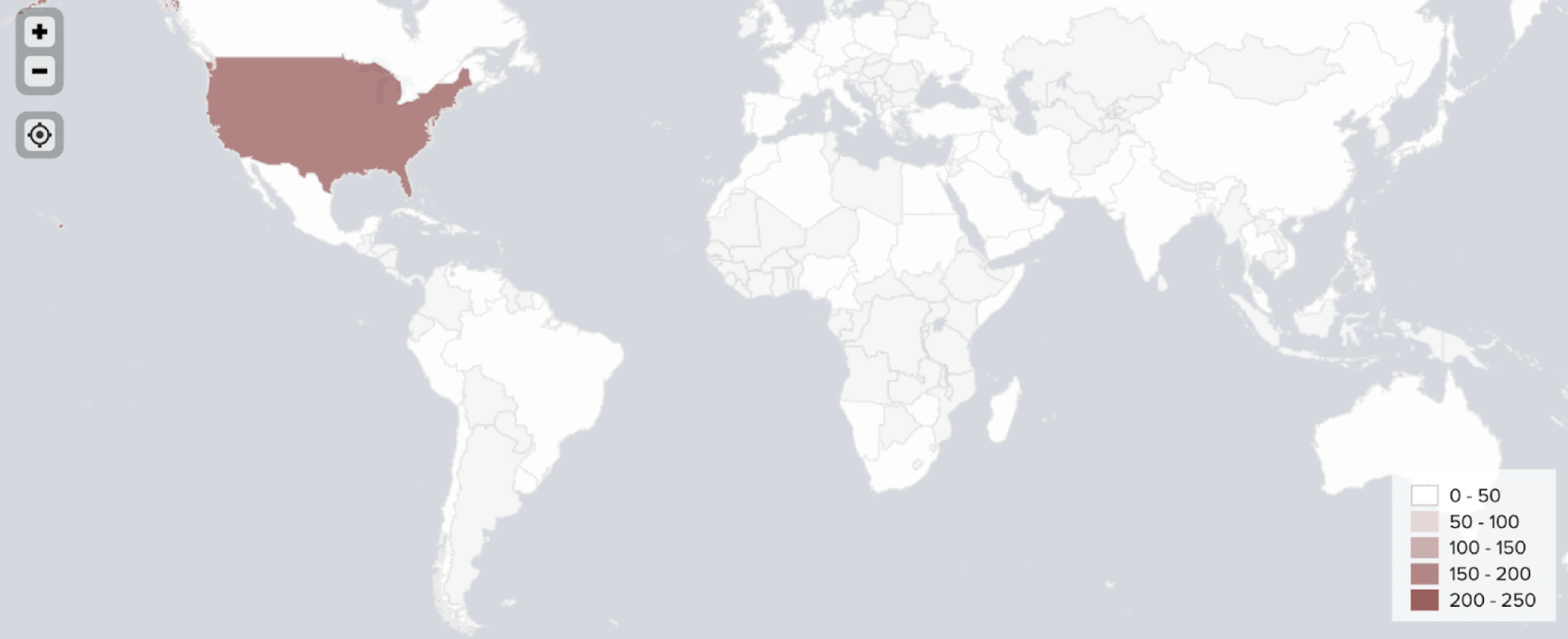
Identifying countries
Four feature vectors are then concatenated for each specific user and fed into the final ensemble model, represented by Voting Classifier. This model is formed by an ensemble of four decision trees, each of which was trained on one of the four feature sets (NER/Language Identification/User Profile Description/Associated Connections Info). The decision tree models employ statistical distribution of users’ data while training, which then allows them to predict the country based on the vector of a specific user that was acquired by processing the four data types described above. Each tree of the ensemble then returns a country as a prediction.
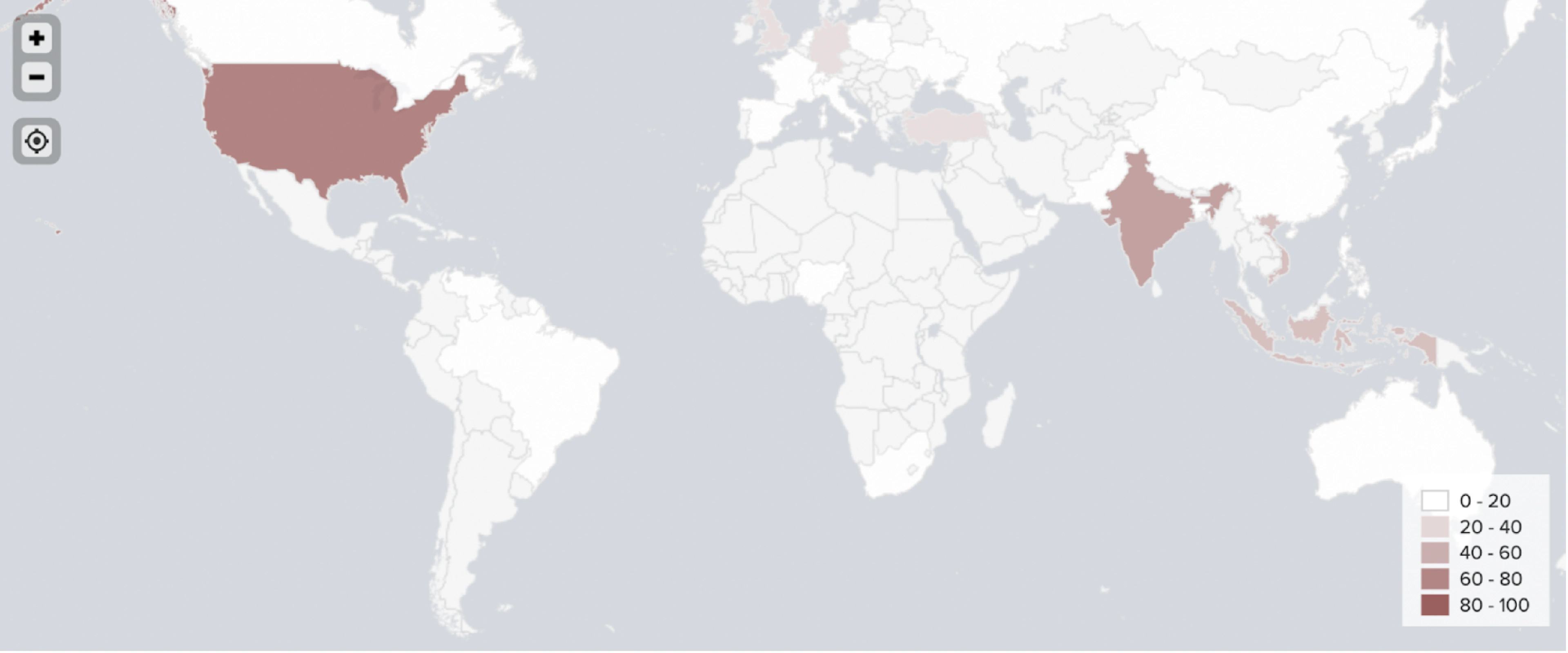
The voting part of the ensemble classifier is trained to assign a probability weight for each of the four predicted countries based on the reliability of each of the four data types. By combining information from the four data types, users which are impossible to identify based on a single data type can be identified in combination with another. For example, the geolocation of a user who has not shared their geolocation, or indicated unreliable information (like moon, earth, aldebaran, crypto etc.), can be accurately identified with their language distribution (whether they tweet in English, Finnish, Japanese or Tagalog, etc.), the Geographical Named Entities they mention (the Eiffel Tower, New York, The Red Square), or the geolocations of the local businesses they follow. As a result, the voting classifier returns the country with the highest probability in consideration of these data types. Moreover, the classifier outputs the final probability of the predicted country, allowing us to establish a reliable confidence threshold.
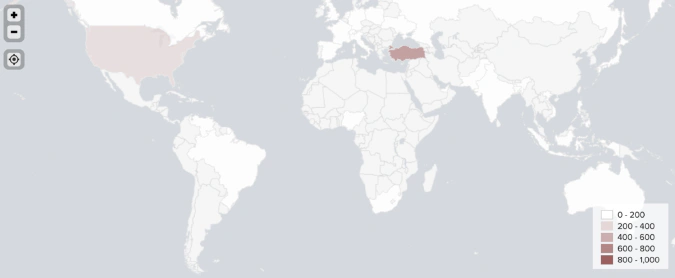
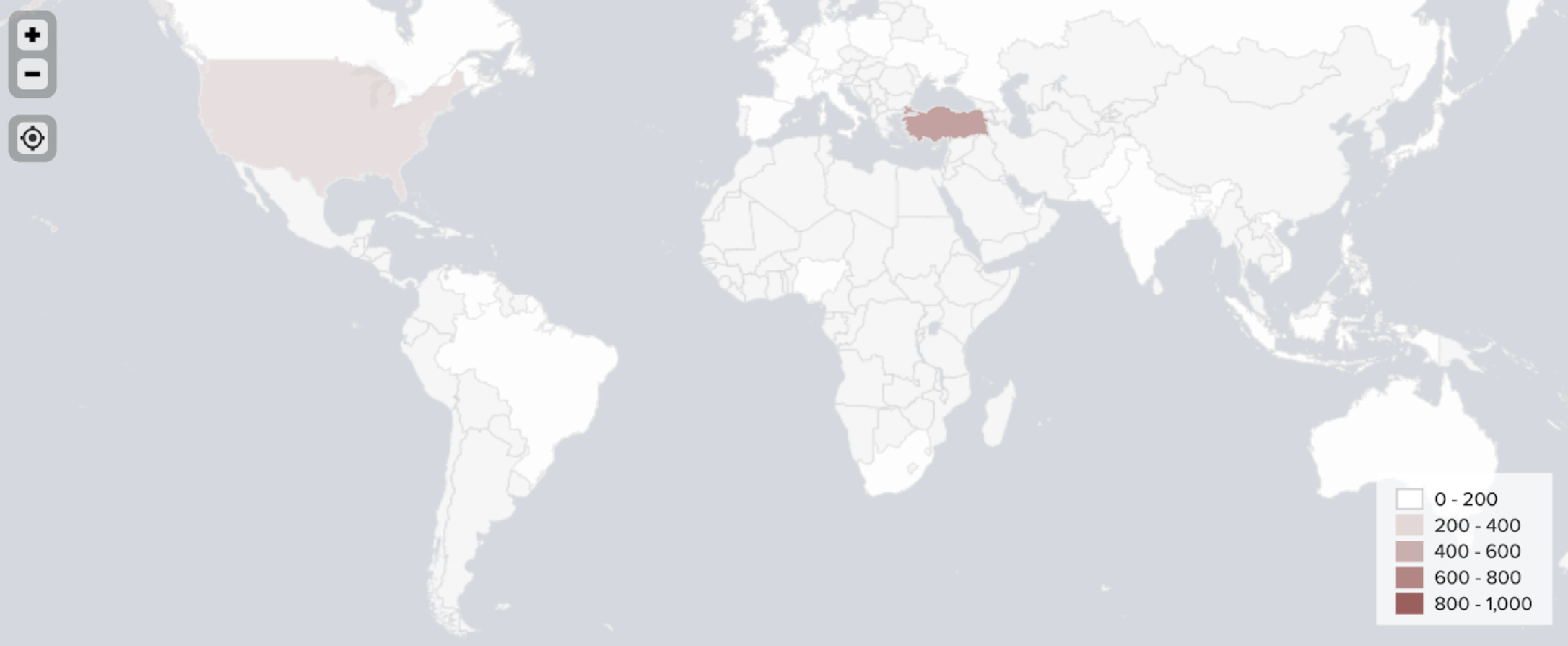
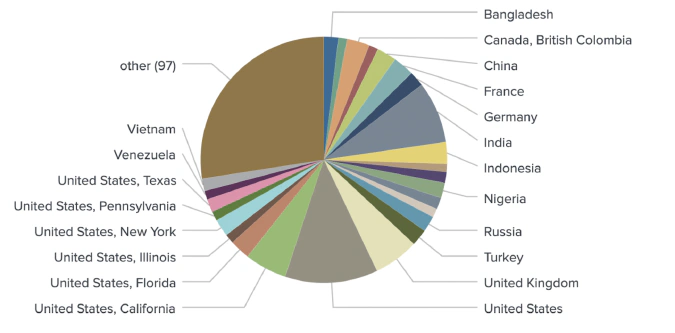
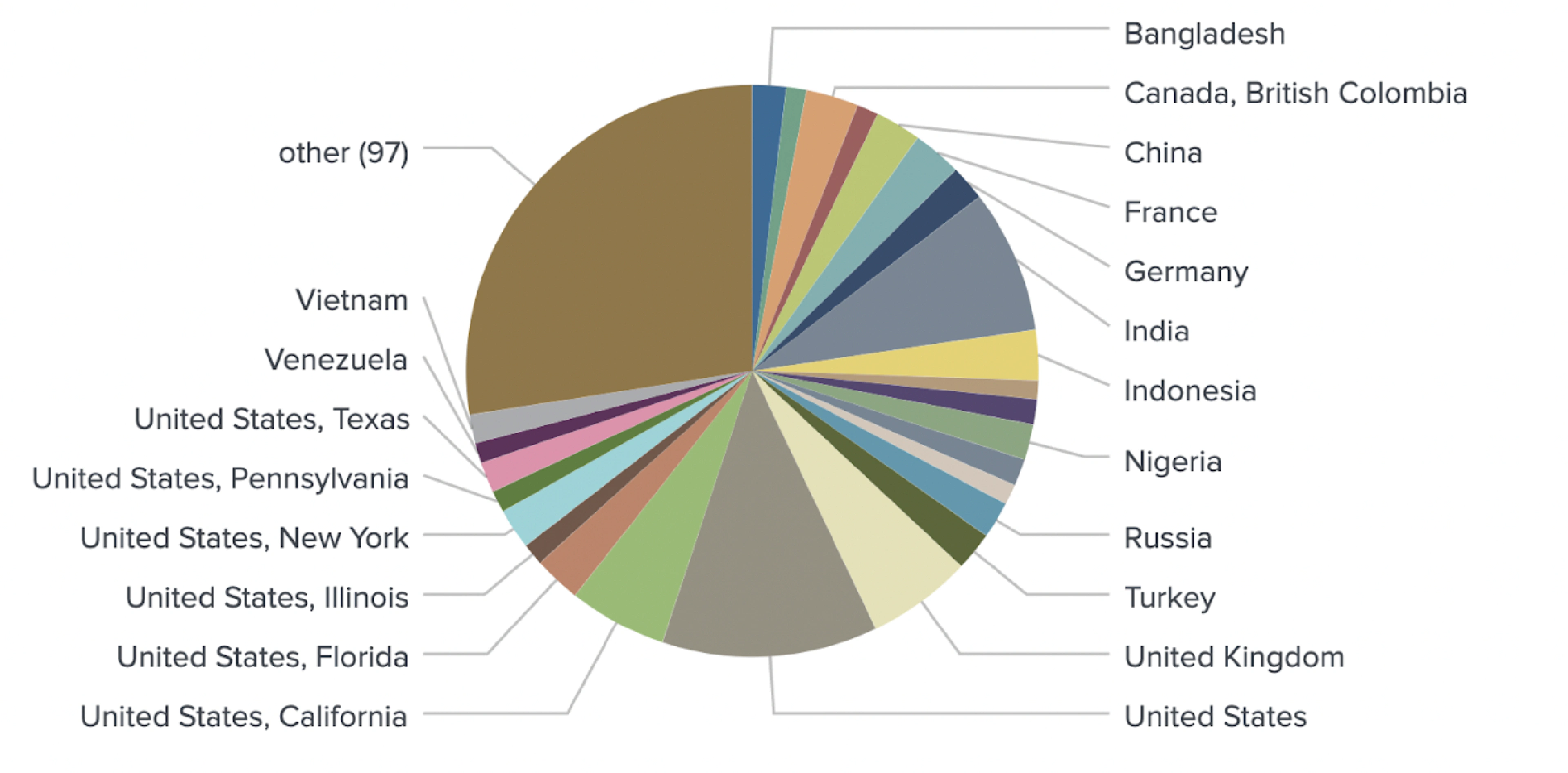
Combining all mentioned geotagging methods in one model produced accurate locations for 1,080 out of 1,289 identified crypto traders.
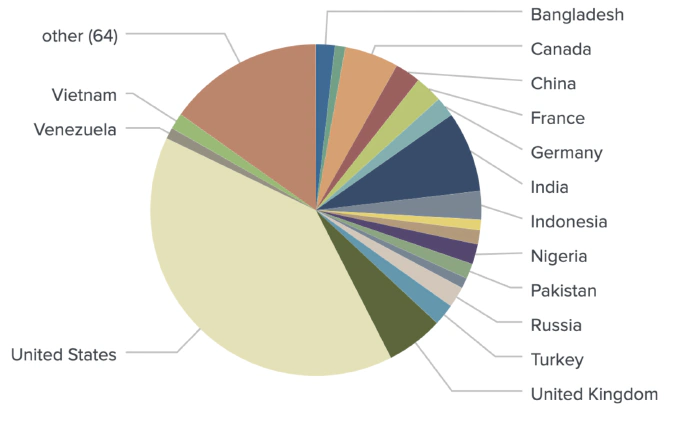
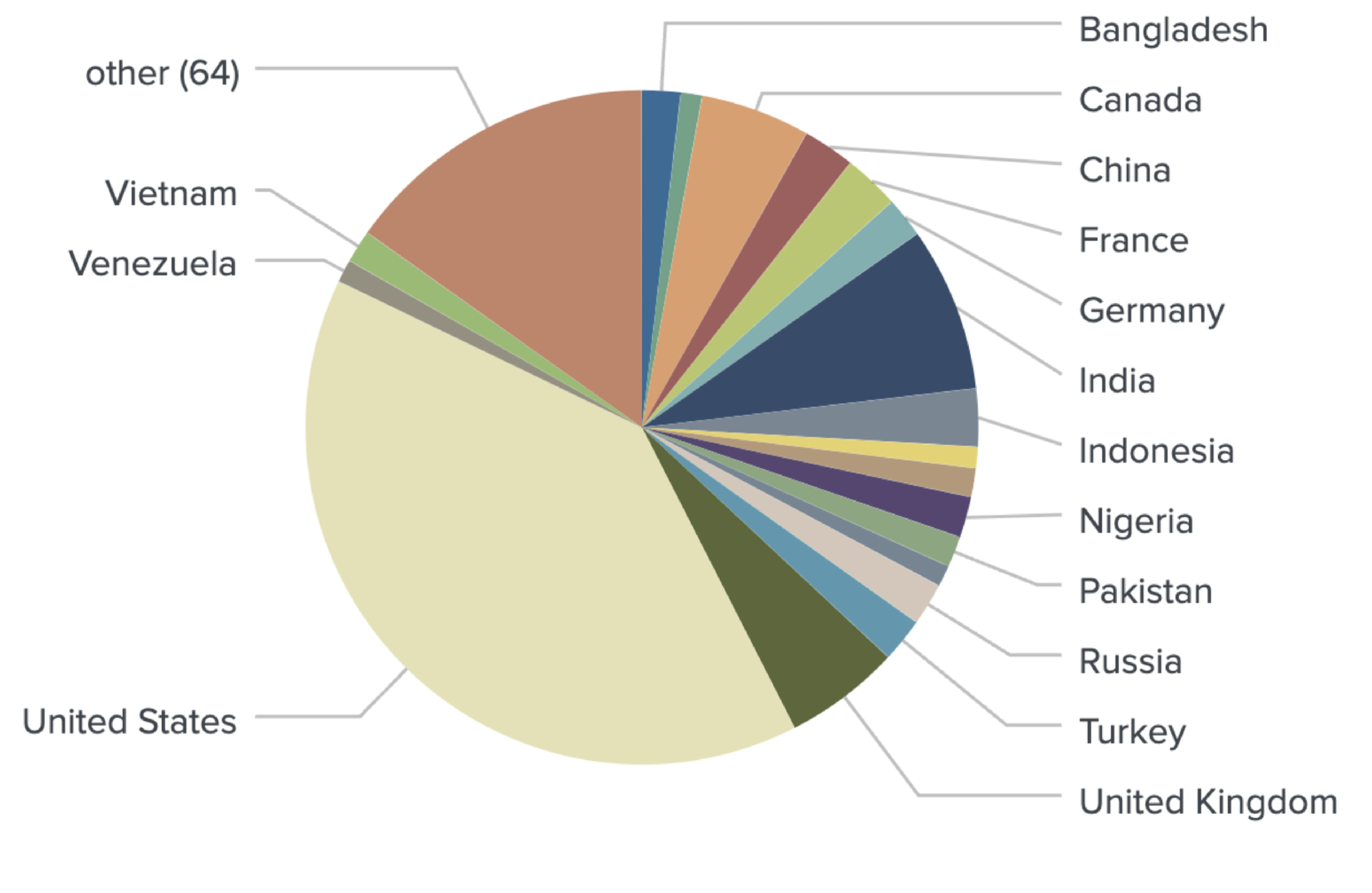
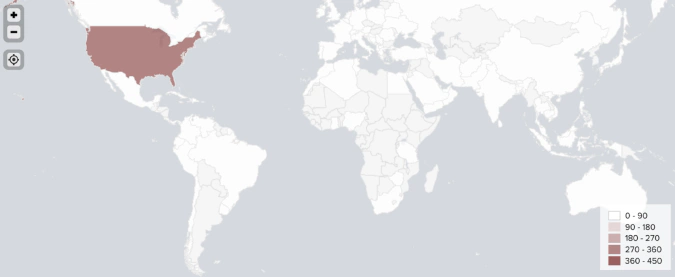
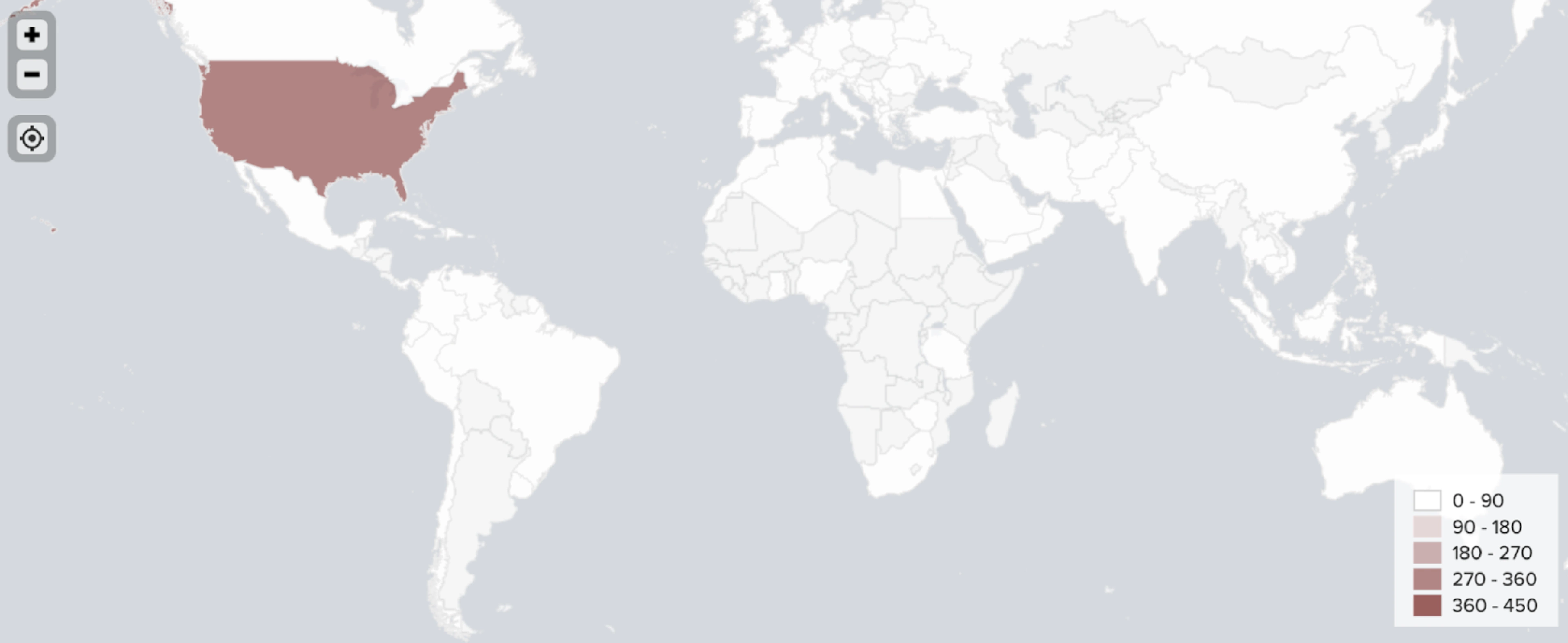
Identifying regions within countries
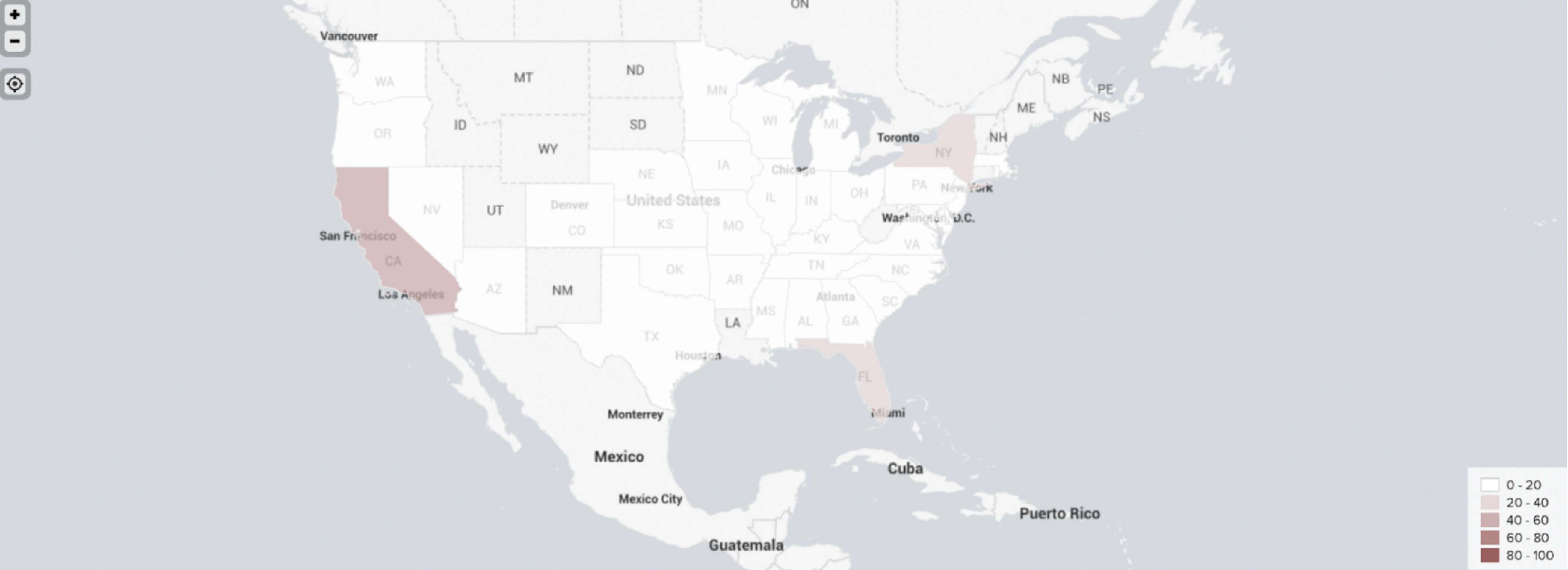
Our enhanced NLP model goes beyond the initial assigning of country tags to each user. Our model is also capable of geotagging users on a state or province level. For example, the model is able to distinguish between a user from New York and a user from Texas.
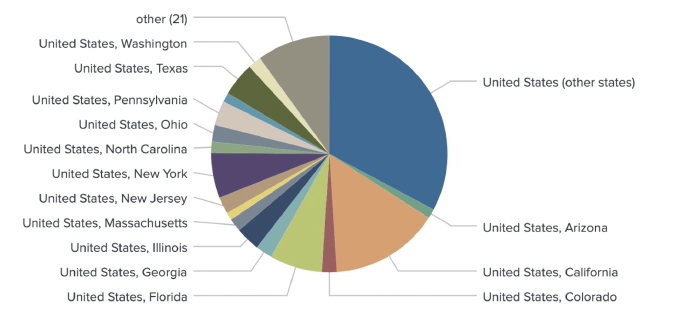
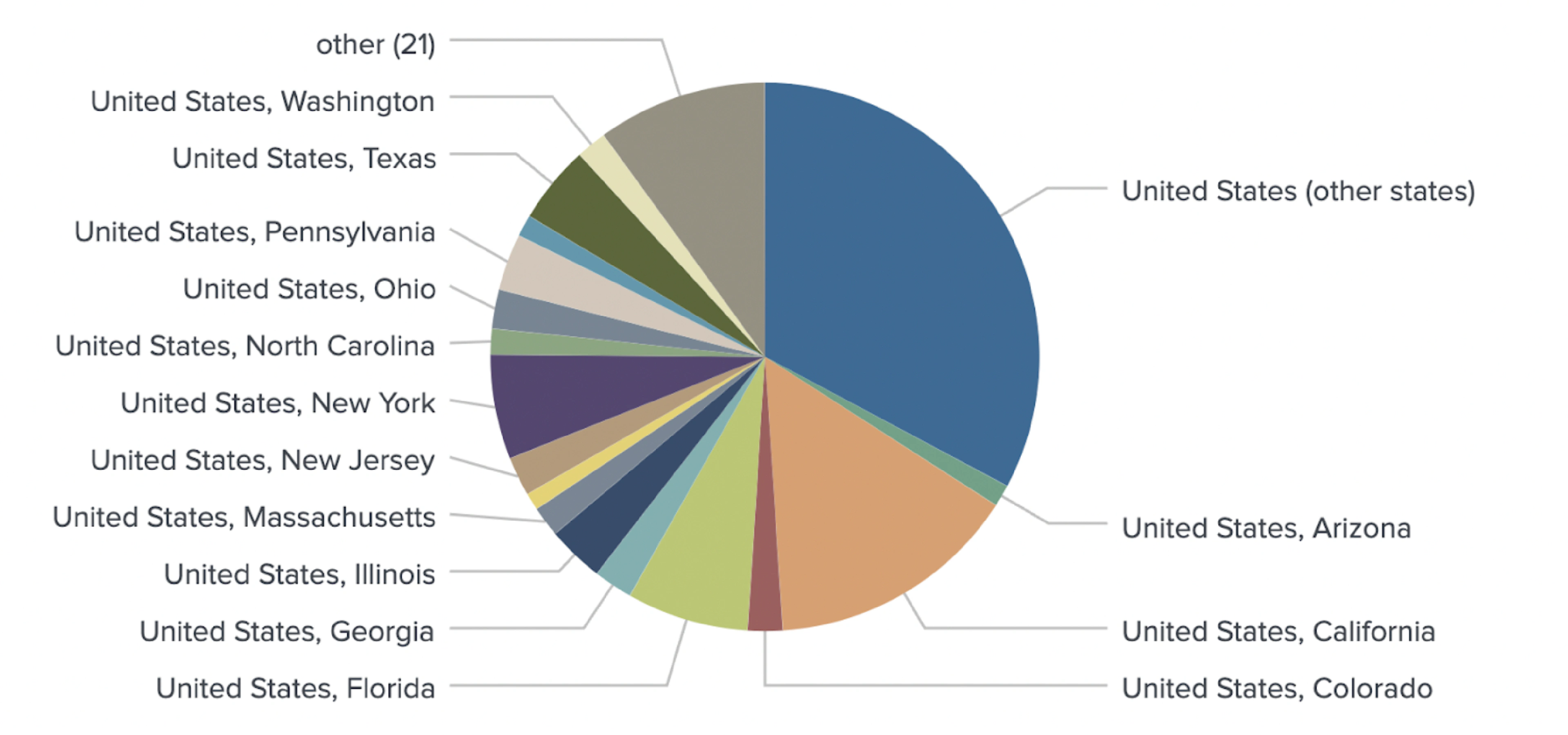
Conclusion
Proactive monitoring of social media and the web allows us to better understand the trading community. As an additional tool to blockchain forensics, market data analysis, and dark web monitoring, our NLP models help in identifying the use of unlicensed crypto products. Furthermore, they help in locating where this activity comes from with a high degree of confidence. By overlaying multiple data types, we’re able to perform a thorough analysis of the customer’s communities and provide insights beyond anything available through existing KYC tools.